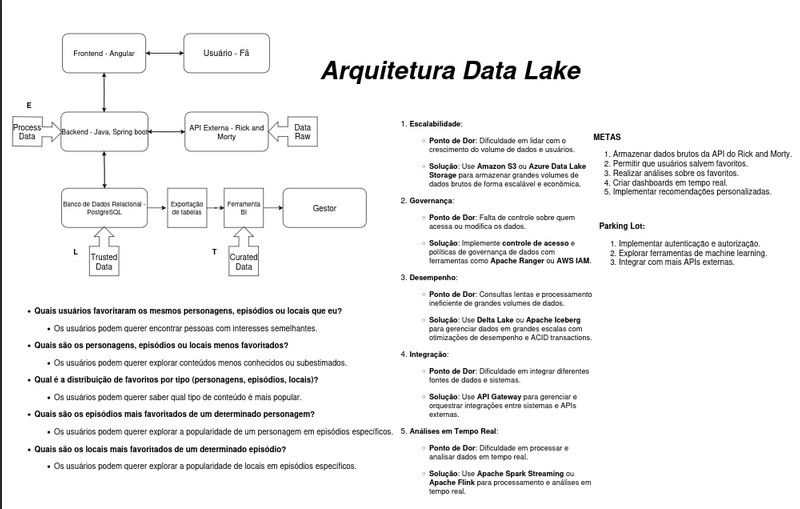
Arquitetura
DataLake
1. Escalabilidade
Ponto de Destaque:
Alimentamos o nosso banco de dados com os dados que antes era consumida da API externa do Rick And Morty. A API é composta por imagens e dados no formato json. Agora conseguimos o projeto pode seguir sem o risco de perder os dados da API externa, além de tudo, os dados são sincronizados para que não haja uma "desatualização" do nosso sistema
Solução:
Para enfrentar esse desafio, usamos os serviços de PostgreSQL para conversão dos arquivos json em entidades relacionáveis. Cloudflare para o upload das imagens da API externa. Essas soluções permitem armazenar grandes volumes de dados brutos de forma escalável e econômica, garantindo que o sistema possa crescer conforme necessário sem comprometer o desempenho.
2. Governança
Ponto de Destaque:
A falta de controle sobre quem acessa ou modifica os dados pode levar a problemas de segurança, conformidade e integridade dos dados.
Solução:
Para garantir uma governança eficaz, é essencial implementar políticas de controle de acesso e governança de dados. Ferramentas como JWT Token e o conceito de Roles of Users podem ser utilizadas para gerenciar permissões e garantir que apenas usuários autorizados tenham acesso aos dados.
3. Desempenho
Ponto de Destaque:
Consultas lentas e processamento ineficiente de grandes volumes de dados podem impactar negativamente a experiência do usuário e a eficiência das análises.
Solução:
Para melhorar o desempenho, recomenda-se o uso de B-Tree, GiST (Generalized Search Tree), uma solução que permite gerenciar dados em grande escala com transações ACID (Atomicidade, Consistência, Isolamento e Durabilidade). Isso garante consultas mais rápidas e um processamento mais eficiente.
4. Integração
Ponto de Destaque:
Integrar diferentes fontes de dados e sistemas pode ser complexo e demorado, especialmente quando se lida com múltiplas APIs e formatos de dados.
Solução:
Para facilitar a integração, sugere-se o uso de um API Gateway. Essa ferramenta gerencia e facilita a integração entre sistemas e APIs externas, garantindo uma comunicação eficiente e segura entre diferentes componentes do sistema.
5. Análises em Tempo Real
Ponto de Destaque:
Processar e analisar dados em tempo real é um desafio, especialmente quando se lida com grandes volumes de dados que precisam ser processados rapidamente.
Solução:
Para análises em tempo real, recomenda-se o uso de Apache Kafkak. Essas ferramentas permitem o processamento e a análise de dados em tempo real, fornecendo insights instantâneos e permitindo a criação de dashboards dinâmicos.
Metas
- Armazenar dados brutos da API do Rick and Morty: Coletar e armazenar dados brutos para análise futura.
- Permitir que os usuários salvem favoritos: Os usuários podem marcar personagens, episódios ou locais como favoritos.
- Realizar análises sobre os favoritos: Analisar padrões e tendências com base nos favoritos dos usuários.
- Criar dashboards em tempo real: Fornecer visualizações em tempo real dos dados analisados.
- Implementar recomendações personalizadas: Oferecer recomendações personalizadas com base nos favoritos e comportamentos dos usuários.
Parking Lot (Tarefas Futuras)
- Implementar autorizações e autenticação: Garantir que apenas usuários autorizados possam acessar o sistema.
- Explorar ferramentas de machine learning: Utilizar técnicas de machine learning para melhorar as recomendações e análises.
- Integrar com mais APIs externas: Expandir a integração com outras APIs para enriquecer os dados e análises.
Perguntas Frequentes
-
Outros usuários favoritaram os mesmos personagens, episódios ou locais que eu?
Os usuários podem encontrar pessoas com interesses semelhantes. -
Quais são os personagens, episódios ou locais menos favoritados?
Os usuários podem explorar conteúdos menos conhecidos ou subestimados. -
Qual é a distribuição de favoritos por tipo (personagens, episódios, locais)?
Os usuários podem saber qual tipo de conteúdo é mais popular. -
Quais são os episódios mais favoritados de um determinado personagem?
Os usuários podem explorar a popularidade de um personagem em episódios específicos. -
Quais são os locais mais favoritados de um determinado episódio?
Os usuários podem explorar a popularidade de locais em episódios específicos.
Conclusão
Este documento descreve uma arquitetura Data Lake robusta e escalável, projetada para lidar com grandes volumes de dados e fornecer análises em tempo real. Com foco em escalabilidade, governança, desempenho, integração e análises em tempo real, essa arquitetura visa oferecer uma experiência rica e personalizada para os usuários, permitindo que eles explorem seus favoritos e recebam recomendações personalizadas.
Details
Data Lake